Table of Contents


What Urban Research in India Really Takes

In the autumn of 2021, a research team working in Ajmer quietly packed up their equipment and left the field. Their work was not complete, but worsening law and order conditions had made it unsafe to continue. The team waited, sought formal permission from the District Collector, and only then returned to resume their research.
This incident, shared during the lecture “Doing Urban Research in the Real World: Methods, Messiness and Meaning” by Neha Malhotra Singh, Pravesh Kumari, Mohammad Mansoor, and Selvam K. at ISPP, captured a reality that rarely appears in policy reports or academic papers: urban research in India is deeply unpredictable.
Fieldwork is not just about surveys and statistics. Researchers must navigate bureaucratic systems, build trust within communities that may distrust outsiders, and work around fragmented or unreliable data systems. The lecture showed that doing urban research in India requires patience, adaptability, and political understanding just as much as methodological precision.
Building the Foundation: Who Lives Where and How Do You Find Them?
Before researchers could study a city, they first had to answer a basic question: who lives there, and how can they be reached through a representative sample?
This foundational stage of research is often invisible, but it determines the reliability of everything that follows. Many urban studies fail quietly at this step because the underlying sampling systems are weak. For its Urban Governance project, Janaagraha initially relied on Polling Parts : India’s smallest electoral geography units, each usually containing around 300 households. On paper, these units seemed ideal because they were administratively defined and linked to voter lists.
In practice, however, the voter lists proved highly unreliable. Scanned records were often unclear, boundaries overlapped, addresses were outdated, and buildings could not be accurately identified. These were not minor inconveniences; they threatened the validity of the entire research design.
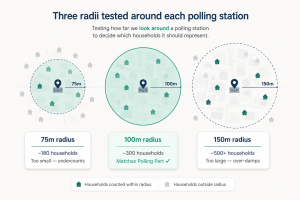
To solve this, the research team created its own sampling framework from scratch. Using QGIS, an open-source geographic information system, they drew circular boundaries around polling stations and tested different radii across pilot locations in multiple cities.
After repeated testing, they found that a 100-metre radius most consistently captured around 300 households closely matching the size of a Polling Part. This radius was then adopted uniformly across all 17 cities in the study.
This technical adjustment may have seemed small, but it was crucial. In many Indian cities, administrative data is often incomplete or inaccurate. As a result, researchers frequently have to build the basic scaffolding of research themselves before they can even begin analysis.
Seeing Class from the Street: Housing as a Proxy
Once the researchers identified where people lived, the next challenge was understanding who they were studying. Measuring socio-economic class in India is notoriously difficult. Income is often under-reported, occupations frequently overlap between formal and informal sectors, and class is shaped not only by money but also by access to state services, markets, and social networks.
Janaagraha addressed this problem by using housing type as a proxy for socio-economic status. Field enumerators walked through neighbourhoods and visually assessed each non-commercial building based on factors such as:
- construction material
- number of floors
- Balconies
- compound walls
- overall structure quality.
Each building was then assigned a housing category on a five-point scale.The logic behind this method was simple but effective: housing often reflects a household’s long-term relationship with the city’s governance systems and economic opportunities better than reported income alone.
Mumbai demonstrated why this approach mattered. More than half of the city’s population lives in slums, yet these settlements are often nearly invisible in conventional datasets. Google Street View does not cover many inner lanes, and satellite imagery frequently reduces dense settlements to indistinguishable clusters of rooftops.
To address this, the team conducted ground-level verification walks, mapped internal lanes through QGIS, and used booster sampling techniques to ensure slum residents were adequately represented in the dataset. This was not only a methodological concern but also a political one. Excluding the hardest-to-reach populations would have systematically erased the experiences of communities most affected by governance failures.

Fieldwork as Negotiation: The Political Economy of Access
The lecture also challenged the idea that researchers are neutral observers who simply collect information from an unchanged environment. In reality, fieldwork is deeply social and political.
Entering a community with surveys, clipboards, and consent forms immediately raises questions:
Who are these researchers? Why are they here? Can they be trusted? Will this information be misused?
The Ajmer incident highlighted this clearly. Communities often respond to researchers based on their previous experiences with institutions and authorities. Resistance to surveys is not necessarily irrational; it may reflect long histories of neglect, exclusion, or mistrust.
The Janaagraha team treated these moments not simply as obstacles, but as insights into how urban governance actually functions. Questions of access revealed deeper realities:
- who controlled local spaces,
- who exercised informal authority,
- who feared state institutions, and
- who felt excluded from governance systems.
Successfully navigating these dynamics required more than technical research training. It demanded political literacy, cultural sensitivity, and patience alongside methodological rigour.

The Data That Was Everywhere and Nowhere
The second major challenge the lecture addressed was not about generating new data but about using data that already existed. On paper, India had vast quantities of urban data. In practice, it was dismembered across dozens of sources, each using different definitions, different geographies, and different reference periods making any holistic understanding of a city’s condition a labour-intensive exercise in manual synthesis.
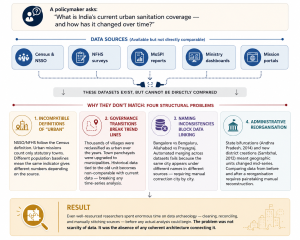
Layered over all of this was a fragmented landscape of national data platforms : CDAP, NDAP, data.gov.in, AAINA, AMPLIFI, IUDX, and SCODUP each individually limited and collectively uncoordinated. Some offered broad sector coverage but weak analytics. Others were simply inaccessible. None provided the integrated, spatially aware, temporally consistent data environment that urban policy actually required.
Several ministry dashboards remained siloed by sector, making any holistic assessment of a city’s condition impossible without significant manual effort. The data ecosystem had grown organically ministry by ministry, mission by mission, portal by portal with no overarching design principle and no single point of access.
Research That Earned Its Findings
What ran through both halves of the lecture, the fieldwork and the data was a single thread: the gap between how research was supposed to work and how it actually worked in Indian cities was not a temporary inconvenience. It was structural. Engaging with it honestly was what made the research credible in the first place.
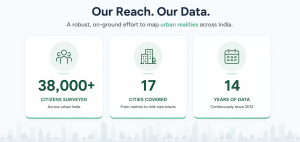
The Janaagraha team’s urban governance project was, by any measure, an extraordinary undertaking: 38,000 respondents, 17 cities, more than a decade of continuous data collection. Its value lay not just in the findings it produced, but in the methodological integrity that underlay them: the willingness to build new sampling frames when existing ones were inadequate, to classify socio-economic status in ways that reflected urban reality rather than administrative convenience, to navigate political resistance with transparency and patience, and to acknowledge the limitations of available secondary data rather than paper over them.
And always, to return as that team in Ajmer did, after the disruption, after the permissions, after the waiting. Not because the data demanded it, but because the people whose lives that data was meant to reflect deserved no less.
Based on a lecture by Neha Malhotra Singh, Pravesh Kumari, Mohammad Mansoor, and Selvam K. from Janaagraha, delivered on 9 January 2026.